
In an AI Forum NZ newsletter yesterday Forum Executive Director Ben Reid said the following:
“Last week, I was part of the delegation at the annual Partnership on AI (PAI) annual all-partners meeting in San Francisco…
…One of the highlights for me was an open and frank speaker panel featuring Kiwi Facebook executive Vaughan Smith which discussed the emerging effects of AI on media and democracy, including the ongoing fallout from Cambridge Analytica and US election manipulation scandals. It was instructive to understand the challenges that social media giants face attempting to automate moderation of literally billions of posts per day. Building algorithmic systems which can keep up with the huge diversity of cultures and languages across the world and effectively automate ethical value based decisions on a global scale is a data science and AI challenge in itself! (Discuss…)”
Interesting point Ben, and since you invited us to ‘discuss’, I don’t mind if I do.
I’ve been doing some thinking on this lately, and for me the issue of information pollution is the #1 priority in the world today, because clean information underpins every decision we make, about every issue, and information pollution is destabilizing, harbors risk and threatens the institutions of democracy.
I can’t speak to the technical issues around monitoring billions of posts (and I prefer the word ‘monitoring’ to ‘moderating’). But I can speak to the theory behind the problems.
One idea I’d like to see pursued is the idea of a ‘Healthy News’ content labeling system. This would target the items with the largest number of views/likes/shares, so it would be top-down and not necessary for a post to be labeled until it’s risen to prominence (thereby reducing scale of the solution).
The labeling system needs to be:
- Extremely simple, yet articulate enough to quickly pass on the relevant information at a glance and further information at a hover
- Grounded in deep technical, proven theory about the dynamics of human information transmission
These dynamics (to greatly simplify the theory that I wrote my Masters and PhD on) boil down to:
- Features of the source of the information
- Features of the content of the information
- Features of frequency of the information
Human psychology has evolved and then developed to attend to these features. This suite of theory (and all it’s nuances) explains why we believe what we do and why certain information is passed on and other information is not.
Different pieces of information (posts, news items, conspiracy theories, fashions, formulae, etc) ‘succeed’ because they have the right combination of these three factors.
All three factors can be traced and quantified in various ways. For example:
* There are programs that allow you to find the original source of a Twitter post, or the first mention of an exact phrase. The source can be categorized as a major thought hub, or a leading expert, or an isolated individual with links to groups that incite violence.
* There are applications that can deduce the emotional tone of the content of a piece of information (and many other content features like the truth of facts through automated real-time fact checking).
* There are algorithms for tallying shares/likes/retweets/views/downloads to establish frequency distributions.
Using these basic features and a host of other metadata we can categorize information according to its source, content and frequency.
We can then use a system of simple colour coded icons to convey that information.
A red robot icon for example combined with a red angry face icon might mean the source of the item is likely a twitter bot, and the emotional tone of the content is aggressive or inciteful.
A green tick icon combined with an orange antenna icon might mean this item passes fact-checking software, but comes from an infrequently liked source.
These are just examples I’m dreaming up. What we need is a research programme that takes the vast literature of cultural evolution theory and human information transmission dynamics theory, and cognitive bias theory and deduces what variables that drive the theory can we extract from network data and what these can tell us about information and its dynamics.
We then need to implement this labelling, and provide education around information transmission dynamics in schools, on websites, everywhere, until people understand how and why this stuff flows the way it does. It will take time, but just as we learned to interpret all the vast array of icons we come across daily, we can grasp this too, and the implications particular icon sets have.
Additionally, hovering over the icons provides additional information about the information transmission dynamics and why this item has spread as it has.
This is a quick first pass at this ‘Healthy News’ labelling idea. But joint work between technical digital media experts and those who understand the science of cultural evolution and cognitive biases could start to deduce how and why this all happens and how we can warn users about dangerous, false, hysterical, manipulative, and malicious content.
I found the following article particularly interesting: https://medium.com/hci-design-at-uw/information-wars-a-window-into-the-alternative-media-ecosystem-a1347f32fd8f
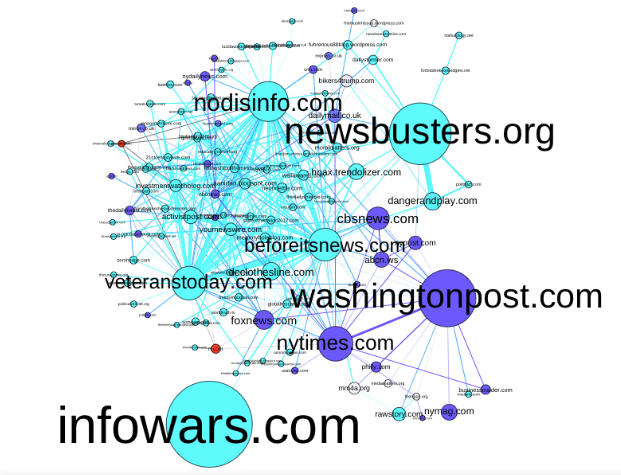
In it they generate this figure from network information harvested:
The caption reads: “we generated a graph where nodes were Internet domains (extracted from URL links in the tweets). In this graph, nodes are sized by the overall number of tweets that linked to that domain and an edge exists between two nodes if the same Twitter account posted one tweet citing one domain and another tweet citing the other. After some trimming (removing domains such as social media sites and URL shorteners that are connected to everything), we ended up with the graph you see in Figure 1. We then used the graph to explore the media ecosystem through which the production of alternative narratives takes place.”
It is this kind of work and the software that drives it, which needs to be combined in the tool for ‘Healthy News’ labeling, ideally using a watermarking system.
The next step will be to fight off those who attempt to manipulate the new system, but that’s another story…
End of discussion.
